“Saying it’s just more of what we had before is like saying a hurricane is just more breeze[i]”.
Thomas de Zengotita
In de zomervakantie voordat ik hier Lector werd, bezocht ik samen met mijn vrouw de stad New York. Veel van jullie zullen daar wel eens geweest zijn en het Vrijheidsbeeld bezocht hebben. Wie dat gedaan heeft weet ook dat de boot ná het Vrijheidsbeeld nog doorvaart naar Ellis Island; het eiland waar aan het einde van de 19e eeuw immigranten in de VS werden geregistreerd.
De plek maakte een onuitwisbare indruk op mij. In de vorige eeuw vonden 12 miljoen immigranten, hun weg naar de VS, veelal Europanen op de vlucht voor hongersnoden. De meesten hadden zich in de schulden gestoken om de overtocht te kunnen maken. Ze moeten bij aankomst tussen hoop en wanhoop geweest zijn. Een enorm zware reis achter de rug, huis en haard verlaten, gelokt door de Amerikaanse Droom – een enorme belofte. Het gevoel wordt goed gevangen in dit citaat van een Italiaanse immigrant:
“I came to America because I heard the streets were paved with gold. When I got here I found out three things: first, the streets weren’t paved with gold; second, they weren’t paved at all; and third, I was expected to pave them.”
 Zowel de initiële goudkoorts als de ontnuchterende reality check die daarna kwam, zullen professionals die in de wereld van digitale media werken bekend voorkomen. Er worden nu gouden bergen beloofd voor Data en Artificiële Intelligentie (A.I.) De verwachtingen zijn zo hooggespannen dat er wel gesproken wordt van de vierde industriële revolutie[ii]. Maar de professionals die het waar moeten maken, die de toepassingen en diensten moeten bedenken waar al dat geld mee verdiend gaat worden, weten vaak helemaal niet waar ze moeten beginnen.
Zowel de initiële goudkoorts als de ontnuchterende reality check die daarna kwam, zullen professionals die in de wereld van digitale media werken bekend voorkomen. Er worden nu gouden bergen beloofd voor Data en Artificiële Intelligentie (A.I.) De verwachtingen zijn zo hooggespannen dat er wel gesproken wordt van de vierde industriële revolutie[ii]. Maar de professionals die het waar moeten maken, die de toepassingen en diensten moeten bedenken waar al dat geld mee verdiend gaat worden, weten vaak helemaal niet waar ze moeten beginnen.
We willen natuurlijk graag toepassingen van Data en A.I. bedenken waar eindgebruikersblij van worden. Maar de toegevoegde waarde van deze nieuwe mogelijkheden voor de gebruiker is helemaal niet altijd duidelijk. Meeslepende toekomstvisies brengen geen brood op de plank. We zullen de beloftes zelf waar moeten maken, stap voor stap en toepassing voor toepassing.
Het belang van User Experience professionals
Ik merk als lector vaak dat de professionals waar het lectoraat zich voor inspant, de “User Experience (UX) professionals, een onbekende beroepsgroep vormen. Toch hebben we elke dag met hun werk te maken.
Onze samenleving is namelijk steeds digitaler geworden. E-mail is tegenwoordig de regel, fysieke post de uitzondering. De reden dat dat er nog iemand aan de deur komt is omdat we online winkelen en ons eten bestellen. Banken hebben haast geen kantoren meer: pinautomaten, apps en contactloos betalen hebben deze overbodig gemaakt. Ook entertainment is gedigitaliseerd: we gamen, we kijken on-demand televisie, we volgen vrienden en beroemdheden via sociale media. Er is haast geen handeling meer te bedenken waar we niet op één of andere manier in contact komen met digitale media.
Al die digitale contactmomenten zijn ontworpen door UX- professionals. Ze hebben mensen bevraagd over wat ze willen van nieuwe technologie, ze hebben meegedacht over functionaliteit en vormgeving en ze hebben de bediening ervan uitgedokterd. Achter de schermen van onze digitale samenleving wordt elke dag een enorme berg werk verzet. Over elke online klik, honderden per persoon per dag, is nagedacht en daar staan we, als het werk goed is uitgevoerd, zelden bij stil.
Ons dagelijkse digitale leven verloopt relatief soepel, en omdat UXers meestal achter de schermen actief zijn, is het nodig om nog eens te onderstrepen hoe groot de prestatie is om dat voor elkaar te krijgen. UXers zijn daar vaak vrij bescheiden over. In ons vakgebied wordt soms gezegd dat we minder volwassen zijn dan andere ontwerpdisciplines zoals werktuigbouwkunde of elektrotechniek. Er wordt gezegd dat we geen equivalent van de maanlanding hebben; geen inspirerend voorbeeld waardoor iedereen kan zien hoever de kennis en kunde in ons vak wel niet gevorderd is.
Dit is onzin. Iets meer dan een halve eeuw geleden was het bedienen van computers nog voorbehouden aan specialisten. Je moest een programmeertaal beheersen om ook maar iets van een computer gedaan te krijgen. Vandaag de dag pakken kinderen zo jong als 3 of ouderen van boven de 90 een tablet, smartphone of laptop vast en doen er zonder enige opleiding dingen mee die in mijn jeugd nog ondenkbaar waren. ‘Onze’ maanlanding heet Microsoft Windows, iOS of Android. Er is nooit een extra journaal aan gewijd, maar iedereen die er oog voor heeft kan elke dag genieten van onze kennis en kunde.
Nieuwe uitdagingen voor UX
Er is nog iets waar we niet vaak bij stil staan in onze digitale omgeving en dat is hoeveel sporen we nalaten van ons gedrag. De meeste views, kliks en andere online handelingen belanden in databases. Zo weten website-eigenaren hoeveel bezoek ze hebben gehad, marketeers hoe aantrekkelijk hun advertenties zijn en kranten welke artikelen populair zijn. Ook UXers kunnen deze data gebruiken om te kijken of de oplossingen die ze bedacht hebben goed werken of dat gebruikers bijvoorbeeld ergens afhaken.
Dit zijn relatief eenvoudige toepassingen van data, maar met veel data en betere wiskunde kan nog veel meer. Computers kunnen tegenwoordig steeds makkelijker spraak en gezichten herkennen. Ze kunnen teksten zelf afmaken (denk aan WhatsApp/Google auto complete) en ze kunnen persoonlijk advies geven. Dit soort complexere data-toepassingen worden meestal aangeduid met het begrip A.I. (Artificiële Intelligentie). Geen van deze voorbeelden is nog toekomstmuziek: ze zijn allemaal al ingebouwd in moderne telefoons.
Het is geen wonder dat UXers, die meestal opgeleid zijn voor het ontwerpen van interactieve toepassingen, maar nog niet voor toepasingen met A.I. (intelligente toepassingen), zich afvragen hoe dat het beste moet[iii]. Zijn de werkprocessen voor het ontwerpen van intelligentie hetzelfde als die voor interactie[iv]? Wat zijn zinvolle toepassingen van intelligentie in het dagelijkse digitale verkeer? Hoe ontwerp je een realistische toepassing van A.I.? Wat kan wel en wat kan niet? En vóór alles: hoe ervaren mensen dit soort toepassingen?
De ervaring van intelligentie
Daarbij zet het woord intelligentie ons eigenlijk op het verkeerde been. We hebben allemaal veel ervaring met intelligentie: onze intelligente familieleden, onze collega’s, onze kinderen en onze huisdieren. Die ervaring met mensen en dieren gebruiken we ook bij het bedenken van intelligente toepassingen. We denken dat intelligente toepassingen kunnen spreken en redeneren, dat ze autonoom, flexibel, nieuwsgierig en onderzoekend zijn, dat ze eigen ideeën en humor hebben en dat ze gevoelig zijn voor ‘de context’.
Laten dit nu net de eigenschappen zijn die moeilijk in te bouwen zijn in computers. De meeste alledaagse toepassingen van A.I.: de autocorrect op onze telefoons, Google Search en Netflix hebben andere karakteristieken. We merken niet op hoe intelligent die zijn omdat we daar indirect van profiteren. Omdat ze relevante aanbevelingen doen, of voor ons raden wat we willen zeggen in een e-mail. Om dit soort toepassingen te kunnen ontwerpen is ‘menselijke’ intelligentie geen goed model, maar moeten we heel nauwkeurig nagaan welk aspect van de gebruikservaring door A.I. bevorderd kan worden.
Binnen het lectoraat gebruiken we de data-gedreven feedbackloop[v] om dat inzichtelijk te maken. Laat ik deze feedbackloop toelichten aan de hand van mijn favoriete ‘intelligente’ toepassing: de Spotify discover weekly lijst. Op basis van mijn luistergedrag, en dat van anderen, berekent muziekdienst Spotify welke muziek ik mooi vind en stelt elke week een lijst samen met speciaal op mij toegesneden suggesties. Geweldig is dat, want op die manier heb ik al heel veel nieuwe muziek ontdekt.
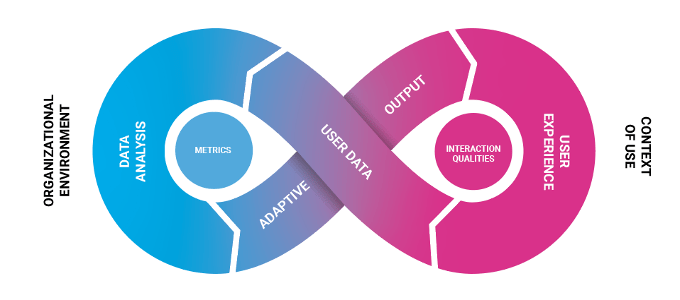
Figuur 1: De data-gedreven feedbackloop
De feedbackloop geeft een relatie weer tussen een data-gedreven dienst (of een intelligent product) en de gebruiker. Deze twee staan aan de buitenkant van het plaatje. Spotify is de organisatie (organizational environment). Aan de andere kant staat de gebruiker. Omdat het nogal afhangt van wat ik aan het doen ben, is het belangrijk die context van gebruik (context of use) ook mee te nemen: ik luister bijvoorbeeld naar de lijst tijdens het hardlopen
Vervolgens kunnen we de vraag stellen hoe Spotify weet wat ik wil luisteren. Dit proces is weergegeven in de lemniscaat in het plaatje. Spotify analyseert mijn luistergedrag (data analysis), stelt op basis daarvan een muzieklijst samen (adaptive output), die ik beluister (user experience), hetgeen Spotify weer registreert (user data). Als ik een nummer niet afluister, is dat voor Spotify misschien reden het de volgende keer niet meer te adviseren.
In het midden van de twee loops vinden we de doelen van die processen. Aan de data- en organisatiekant vinden we metrics. Een metric geeft weer wat een algoritme of de menselijke data-analist uit de data probeert te herleiden. Spotify heeft metrics voor mijn smaak. In de praktijk deelt Spotify mij waarschijnlijk in bij gebruikers met dezelfde smaak: een smaaksegment.
Aan de gebruikerskant vinden we de interactiekwaliteiten. Deze geven de persoonlijke ervaring van een gebruiker met een product of dienst kernachtig weer. Interactiekwaliteiten zijn die aspecten van de interactie die we willen versterken met A.I. Spotify kan mij een persoonlijke relevante selectie muziek voorschotelen en steeds meer relevantere content suggereren. We kunnen de Spotify ervaring evalueren door aan gebruikers te vragen of ze de aanbevelingen inderdaad persoonlijk relevant vinden.
De interactiekwaliteiten van intelligente producten
Waar we zonder de data-gedreven feedbackloop nog terug moesten vallen op onze eigen ervaring met ‘menselijke’ intelligentie – hetgeen een slecht model is voor het soort intelligentie dat we in computers kunnen inbouwen – hebben we nu iets in handen waardoor we intelligentie kunnen ontwerpen vanuit de boogde gebruikservaring. Als we de interactiekwaliteiten van A.I. kunnen benoemen, kunnen we immers ook nadenken over toepassingen waar die kwaliteiten van pas komen. Vervolgens kunnen we het onderliggende systeem, de feedbackloop, verder uitwerken.
Ik kan hier natuurlijk niet ingaan op alle kwaliteiten die data en A.I. aan online interacties kunnen toevoegen, maar de bekendste vijf wil ik toch kort toelichten aan de hand van bekende voorbeelden en van werk uit ons eigen lectoraat.
Naadloosheid (Seamlessnes)
Een interactie is naadloos als je zonder hindernissen van begin tot eind komt. Dat naadloze interactie een ideaal is van interactieontwerpers blijkt bijvoorbeeld uit de titel van het boek “Don’t Make me Think!” van Steve Krug[vi]. Het steekt UXers wanneer ze zien dat de gebruiker moet uitdokteren hoe een site of app werkt of wanneer een handeling onnodig ingewikkeld is.
A.I. kan bijdragen aan naadloze interactie door stappen in die interactie te automatiseren. Chat apps hebben vaak een auto complete functie om het chatten naadlozer te maken door typefouten automatisch te corrigeren. Dat kan tot ergerlijke fouten leiden, maar vaker voorkomt het veel gedoe. Van verreweg de meeste correcties heb je eigenlijk geen weet. Ook Google Search is een voorbeeld. Toen ik kortgeleden naar een coronatest op zoek was kreeg ik de suggestie “Coronatest Den Bosch” al na het typen van de eerste 7 letters “coronat”. Als je erbij stil staat hoe lastig het is om een zoekterm te voorspellen op basis van een paar letters is dat een duizelingwekkende prestatie, waarbij Google natuurlijk gebruik maakt van mijn locatie, zoekgeschiedenis en van wat we collectief zoeken op dit moment. Ik had in 7 letters en een handjevol klikken een afspraak. Naadlozer kan het haast niet.
De verwachting is dat dit soort gedeeltelijke automatisering van online taken een nog grotere vlucht gaat nemen, met name bij hulpmiddelen die onze productiviteit kunnen vergroten. Er zijn bijvoorbeeld e-mailprogramma’s die het schrijven van sommige e-mails voor je over kunnen nemen of die e-mail voorsorteren op basis van de afzender.
Relevantie (Relevance)
Relevantie is de drijvende kracht achter veel aanbevelingssystemen. Aanbevelingssystemen zitten ingebouwd in streaming diensten voor muziek en video. Ook sociale media gebruiken ze om tijdlijnen te organiseren, online winkels om meer te verkopen en datingapps om de liefde een steuntje in de rug te geven. De gedachte is dat de dienst op basis van jouw keuzes in het verleden iets weet over datgene wat je nu wilt kijken, luisteren, kopen of over wie je nu wilt daten.
We zijn in deze wereld van informatieovervloed erg afhankelijk van aanbevelingssystemen. Als je alle berichten op Twitter moest lezen of iedereen op Tinder moest daten voordat je een keuze kon maken, zou het online leven een stuk minder prettig zijn. Keuzevrijheid is misschien fijn, maar dat is dat extra steuntje in de rug van een aanbevelingsdienst eveneens.
Het is een beetje de vraag hoe goed de huidige generatie aanbevelingssystemen precies is[vii]. Toen Spotify met de Discover Weekly dienst kwam, stelden de engineers dat Spotify je muzieksmaak beter kon inschatten dan je beste vrienden. Maar toen we zelf straatinterviews gingen doen over dit onderwerp hielden veel gebruikers het erop dat er “soms wel wat tussen zat”[viii]. Deze mismatch heeft waarschijnlijk te maken met de contextgevoeligheid van je muziekkeus: Spotify kan je smaak aardig inschatten, maar de stemming van het moment veel minder goed[ix].
Natuurlijk kunnen de metrics in deze systemen nog verbeterd worden, maar in het lectoraat verkennen we nog een andere manier om adviessystemen te verbeteren. We verkennen of het mogelijk is gebruikers meer bedieningsmogelijkheden te geven, zodat ze bijvoorbeeld kunnen instellen wat hun stemming op dat moment is of welke data meegenomen moet worden in het advies. Zulke bediening maakt algoritmen transparanter en helpt de gebruiker er meer uit te halen. We denken dat hier nog veel winst te behalen valt.
Betrokkenheid (Engagement)
Met betrokkenheid bedoelen we de mate waarin een digitaal product, een spel of een film de gebruiker in de beleving weet te trekken en weet vast te houden. Als je een boek niet weg kan leggen of wanneer je tot diep in de nacht aan het gamen bent, weet je dat de maker erin geslaagd is je te betrekken in het product.
A.I. kan bijdragen aan betrokkenheid door de gebruiker inhoud voor te schotelen die hem of haar raakt. Dit zien we voortdurend in tijdlijnen van sociale media, waar berichten die veel stof doen opwaaien hogere prioriteit krijgen. Het gebeurt ook in digitale spellen waar de uitdaging van het spel aangepast kan worden aan het spelgedrag van de gebruikers.
Hoewel je bij betrokkenheid misschien vooral denkt aan gameverslaving of verspilde tijd op Facebook, is het een essentiële kwaliteit van digitale media die voor positieve doeleinden ingezet wordt. Serious games kunnen op deze manier gebruikers voor een langere tijd betrokken houden bij de training en/of content van een game, wat noodzakelijk is om uiteindelijk de gewenste kennis-, attitude- of gedragsverandering teweeg te brengen. Deze ‘duurzame’ betrokkenheid vraagt van digitale producten dat zij zich continue kunnen aanpassen aan de veranderende mediavaardigheden en –voorkeuren van gebruikers.
Sympathiek (Relatable)
Uit een ander vaatje tappen ontwerpers die interfaces sympathiek willen laten zijn. Ze zijn er actief op uit een relatie op te bouwen met de gebruiker. Dit zien we bijvoorbeeld terug in virtuele karakters of in dialogen in chatbots. Als gebruikers een band voelen met een toepassing stellen ze zich meestal coörperatiever op en dat kan heel handig zijn als je iets gedaan wilt krijgen van elkaar.
A.I. kan helpen om sympathie te wekken door adequaat te reageren op wat een gebruiker doet in een interactie. Zorgrobots maken hier gebruik van en chatbots in de helpdesk industrie ook. Wij hebben zelf naar relatability gekeken in het verbeteren van vragenlijsten voor tieners. Als we signalen vonden in de data dat pubers een vraag minder serieus namen, probeerden we ze met een virtueel karakter weer op het spoor te zetten. Het virtuele karakter keek de puber bijvoorbeeld vragend aan als hij een antwoord op een gevoelige vraag “rook je” veranderde nadat er allerlei vervolgvragen over gesteld werden.
Betrouwbaarheid (Trustworthiness)
Als laatste kwaliteit wil ik ingaan op betrouwbaarheid. Omdat het zo laagdrempelig is om online content te produceren of interacties aan te gaan, wordt er ook veel misbruik van gemaakt. Er wordt nepnieuws gemaakt om financiële en politieke redenen, er is online bedrog via WhatsApp en criminelen proberen vaak met succes via e-mails persoonsgegevens te achterhalen. Om onze online omgeving leefbaar te houden, zijn poortwachters nodig die ons helpen onze tijd en aandacht te geven aan dingen die belangrijk zijn en ongewenste items buiten de deur te houden.
Ook hier kan A.I. een bijdrage leveren. A.I. wordt al gebruikt om hate-speech en nepnieuws te bestrijden en ze zitten al in de spamfilters die onze e-mailstromen enigszins behapbaar houden. Wat echter opvalt is dat er nog weinig producten op de markt zijn om mensen in staat te stellen deze online beveiliging en filtering in te zetten. We gaan er vanuit dat platform aanbieders zoals Facebook en Twitter voor onze online veiligheid zorgen, terwijl we dat misschien beter aan een onafhankelijke partij zouden kunnen overlaten. De virusscanner is misschien de enige grote uitzondering.
Ons lectoraat denkt dat het nodig is om beter onderzoek te doen naar hoe we online veiligheid, online hygiëne en de betrouwbaarheid van online interacties kunnen verbeteren en hoe data-gedreven diensten daar een uitkomst kunnen bieden.
Tot slot
We klikken ons wat af in het dagelijkse bestaan en of die interacties deugdelijk ontworpen zijn maakt veel uit. Het maakt het verschil tussen plezier en frustratie. Tussen lekker bezig zijn op je werk of je dom en incompetent voelen. Tussen verslavende games of prullen die na één keer in de hoek wil smijten. Ons lectoraat houdt zich elke dag bezig met hoe de digitale samenleving voelt.
Ik hoop dat ik heb kunnen laten zien hoe belangrijk dat is. Ooit was een goede gebruikservaring een dure manier om te zeggen dat iets bruikbaar was. Tegenwoordig ligt de lat hoger en zullen ontwerpers voor specifieke aspecten van de ervaring moeten kunnen ontwerpen. Daarom is het nodig deze interactiekwaliteiten te benoemen. Want als we het soort ervaringen waar toepassingen om vragen kunnen benoemen dan hebben we machtig gereedschap in handen. We kunnen dan toepassingen ontwerpen met meer kwaliteit, we kunnen dan evalueren of de beloofde meerwaarde in de gebruikservaring ook door gebruikers ervaren kan worden en dat geeft weer richting in het ontwerp. Dit was altijd al belangrijk, maar het is onmisbaar bij het ontwerpen van intelligente toepassingen met Data en A.I. Uiteindelijk is het niet de intelligentie zelf die we ervaren, maar wat die intelligentie voor ons doet in de interactie.
Blijf HE&MD missies volgen
Mocht je ons willen volgen, geef onderaan deze pagina je emailadres op waar je de updates van onze missies wilt ontvangen.
[i] De Zengotita, T. (2006). Mediated: How the media shapes your world and the way you live in it. Bloomsbury Publishing USA.
[ii] Schwab, K. (2017). The fourth industrial revolution. Currency.
[iii] Holmquist, L. E. (2017). Intelligence on tap: artificial intelligence as a new design material. Interactions, 24(4), 28-33.
[iv] Yang, Q., Steinfeld, A., Rosé, C., & Zimmerman, J. (2020, April). Re-examining whether, why, and how human-ai interaction is uniquely difficult to design. In Proceedings of the 2020 chi conference on human factors in computing systems (pp. 1-13).
[v] Smits, A., Van Turnhout, K., Hekman, E., & Nguyen, D. (2020). Data-driven design. In DS 104: Proceedings of the 22nd International Conference on Engineering and Product Design Education (E&PDE 2020), VIA Design, VIA University in Herning, Denmark. 10th-11th September 2020.
[vi] Krug, S. (2000). Don’t make me think!: a common sense approach to Web usability. Pearson Education India.
[vii] Schrage, M. (2020). Recommendation Engines. MIT Press.
[viii] https://hemdmissies.nl/aanbevelingen-van-spotify-enthousiasme-maar-toch-ook-veel-twijfels/
[ix] Smits, A. (2021) What Arguing with our Navigation Systems and Spotify Recommendation Can Teach Us About Data Driven Design. Data-bias symposium, Utrecht. Available from https://www.data-empowerment.nl/index.php/2021/04/26/what-arguing-with-our-navigation-systems-and-spotify-recommendation-can-teach-us-about-data-driven-design/
Presentatie foto Jack T on Unsplash